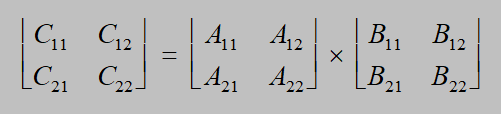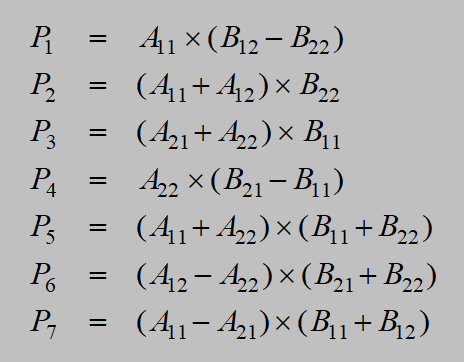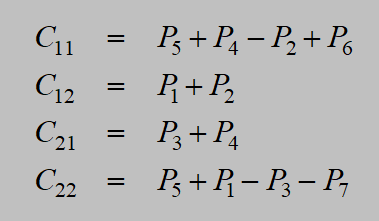基础数据结构与算法
第一章:线性结构
顺序表
对于一个顺序表,我们可以不需要因为结点逻辑关系额外增加开销,逻辑结构和存储结构一致;
做到
顺序表模板类
#pragma once
template < typename T> class SeqList { private :
#define _OVERFLOW 3
#define _ERROR - 1
#define _OUT_OF_RANGE - 1
#define _MAXSIZE 1024
#define _FAIL - 1
T * elem;
int _size= 0 ;
int _capacity= 0 ;
public :
SeqList ( ) { elem= new T[ _MAXSIZE] ;
if ( ! elem) {
std:: cout<< " OVERFLOW" << std:: endl;
exit ( _OVERFLOW ) ;
} = 0 ;
_capacity= _MAXSIZE;
} ~SeqList ( ) { delete[] elem;
elem= nullptr ; } const void clear ( ) { _size= 0 ;
_capacity= _MAXSIZE;
} int size ( ) const { return _size;
} bool empty ( ) const {
return _size== 0 ;
} const T& at ( int index ) const {
if ( index< 0 || index> _size) {
std:: cout<< " ERROR:ArrayIndexOutOfBoundsException" << std:: endl;
exit ( _OUT_OF_RANGE ) ;
} return * ( elem+ index) ;
} const T* begin ( ) const { return elem;
} const T* end ( ) const { return elem+ _size;
} const T& front ( ) const { return * elem;
} const T& back ( ) const { return * ( elem+ _size- 1 ) ;
} & operator[] ( int index ) { return * ( elem+ index) ;
} const T& operator[] ( int index ) const { return * ( elem+ index) ;
} const T* find ( const T* beg , const T* end , const T& value ) const {
for ( const T* tmp= beg; tmp!= end; tmp+ + ) {
if ( * tmp== value) return tmp;
} return this -> end ( ) ; } int capacity ( ) const { return _capacity; } SeqList ( const SeqList& x ) { _size = x. size ( ) ;
_capacity = x. capacity ( ) ;
elem = new T[ _capacity] ;
if ( ! elem) {
std:: cout<< " OVERFLOW" << std:: endl;
exit ( _OVERFLOW ) ;
} for ( int i = 0 ; i < x. size ( ) ; i+ + ) {
elem[ i] = x[ i] ;
} } bool operator== ( const SeqList& r ) const {
if ( this -> _size != r. _size ) return false ; for ( int i= 0 ; i< this -> _size ; i+ + ) {
if ( this -> elem [ i] != r. elem [ i] ) return false ;
} return true ;
} bool operator!= ( const SeqList& r ) const {
return ! ( ( * this ) == r) ;
} < T> & operator= ( const SeqList< T> & x ) {
if ( this != & x) {
delete[] elem;
_size= x. size ( ) ;
_capacity= x. capacity ( ) ;
elem= new T[ _capacity] ;
if ( ! elem) {
std:: cout<< " OVERFLOW" << std:: endl;
( _OVERFLOW) ;
} for ( int i= 0 ; i< x. size ( ) ; i+ + ) {
elem[ i] = x[ i] ;
} return * this ;
} } void insert ( int pos , T value ) {
if ( _size== _capacity) { _capacity*= 2 ;
T* upd_elem= new T[ _capacity] ;
if ( ! elem) {
std:: cout<< " OVERFLOW" << std:: endl;
exit ( _OVERFLOW ) ;
} for ( int i= 0 ; i< _size; i+ + ) {
upd_elem[ i] = elem[ i] ;
} delete elem;
elem= upd_elem;
} if ( pos>= _MAXSIZE) {
std:: cout<< " OVERFLOW" << std:: endl;
exit ( _OVERFLOW ) ;
} else if ( pos< 0 || pos> _size) {
std:: cout<< " ERROR:ArrayIndexOutOfBoundsException" << std:: endl;
exit ( _OUT_OF_RANGE ) ;
} for ( int i= _size; i> pos; i- - ) {
elem[ i] = elem[ i- 1 ] ;
} [ pos] = value;
_size+ + ;
} void push_back ( T& value ) {
insert ( this -> _size , value) ;
} void erase ( int pos ) {
if ( pos>= _MAXSIZE) {
std:: cout<< " OVERFLOW" << std:: endl;
exit ( _OVERFLOW ) ;
} else if ( pos< 0 || pos>= _size) {
std:: cout<< " ERROR:ArrayIndexOutOfBoundsException" << std:: endl;
exit ( _OUT_OF_RANGE ) ;
} for ( int i= pos; i< _size; i+ + ) {
elem[ i] = elem[ i+ 1 ] ;
} - - ;
} } ;
单链表
对于一个头部带哑结点的单链表,指针必须遍历整个单链表,最坏时间复杂度为
尽管对于单链表的插入与删除操作的复杂度为
对于单链表的各个变形都稍微分析优缺点:
不带头部的单链表:在实际实现中,对于结点是否是第一个需要反复判断,特殊处理;并且由于有头部节点的存在,使得空表和只有头结点的表处理起来一样;
循环单链表:
在最后一个结点指针域存放第一个结点的地址,形成一个环 ;
判断遍历是否终止条件改为 p->next==head;
带尾指针的循环单链表
在合并两个循环单链表的场景可以将复杂度将为
双向链表:是STL中 std::list容器的底层实现,支持高效寻找前驱的操作,是以时间换空间的策略;
静态链表:喜闻乐见的比赛专用,码量小,静态空间;
下面给出单链表和双向链表的模板类实现:
单链表模板类
#pragma once
template < typename T> class ListNode {
private :
ListNode< T> * _next;
T _data;
public :
friend class List; ListNode ( const T& item , const ListNode< T> & ptr = nullptr ) {
this -> _data = item;
this -> _next = ptr;
} ListNode ( const T& item = 0 ) { this -> _data = item; this -> _next = nullptr ; } ~ListNode ( ) { _data= 0 ;
delete _next;
_next= nullptr ;
} & data ( ) { return this -> _data ; } void data ( const T item ) { this -> _data = item; } < T> * next ( ) { return this -> _next ; } void next ( const ListNode< T> * ptr ) { this -> _next = ptr; } } ;
template < typename T> class List {
private :
ListNode< T> * _head;
int _size;
#define _INVALID_INDEX - 1
#define _FAIL - 1
#define _OVERFLOW 3
public :
friend class ListNode;
List ( ) {
this -> _head = new ListNode< T> ;
_head-> data = 0 ;
_head-> next = nullptr ;
_size= 0 ;
} < T> * head ( ) const { return this -> _head ; } const int size ( ) const { return this -> _size ; } bool empty ( ) const { return ( this -> _head ) -> _next == nullptr ; } const T& at ( int pos ) { ListNode< T> * tmp= this -> _head ;
int cnt= 0 ;
while ( tmp) {
if ( cnt== pos) return tmp-> _data ;
cnt+ + ;
tmp= tmp-> _next ;
} :: cout<< " INVALID_INDEX" << std:: endl;
exit ( _INVALID_INDEX ) ;
} & operator[] ( int pos ) {
ListNode< T> * tmp= this -> _head ;
int cnt= 0 ;
while ( tmp) {
if ( cnt== pos) return tmp-> _data ;
cnt+ + ;
tmp= tmp-> _next ;
} exit ( _INVALID_INDEX ) ;
} const T& operator[] ( int pos ) const { ListNode< T> * tmp= this -> _head ;
int cnt= 0 ;
while ( tmp) {
if ( cnt== pos) return tmp-> _data ;
cnt+ + ;
tmp= tmp-> _next ;
} exit ( _INVALID_INDEX ) ;
} < T> * at_pos_ptr ( int pos ) {
ListNode< T> * tmp= this -> _head ;
int cnt= 0 ;
while ( tmp) {
if ( cnt== pos) return tmp;
cnt+ + ;
tmp= tmp-> _next ;
} :: cout<< " INVALID_INDEX" << std:: endl;
exit ( _INVALID_INDEX ) ;
} < T> * find ( int value ) {
ListNode< T> * tmp= _head-> _next ;
while ( tmp) {
if ( tmp-> _data == value) return tmp;
else tmp= tmp-> _next ;
} if ( ! tmp) {
std:: cout<< " FAIL" << std:: endl;
exit ( _FAIL ) ;
} } void insert ( int pos , T value ) {
ListNode< T> * pre= this -> at ( pos- 1 ) ; ListNode< T> * tmp = new ListNode < T> ( value ) ; tmp-> _next = pre-> _next ;
pre-> _next = tmp;
this -> _size + + ; } void erase ( int pos ) {
ListNode< T> * pre= this -> at ( pos- 1 ) ;
ListNode< T> * now= pre-> _next ;
ListNode< T> * nxt= now-> _next ;
pre-> next = nxt;
delete now;
} List ( const List< T> & x ) {
this -> _head = new ListNode< T> ;
ListNode< T> * tmp= _head-> _next ;
ListNode< T> * tmpx= x. _head -> _next ;
while ( tmp) {
tmp-> _data = tmpx. _data ;
tmp-> _next = tmpx. _next ;
tmp= tmp-> _next ;
tmpx= tmpx. _next ;
} return * this ;
} ; bool operator== ( const List< T> & r ) const {
if ( this -> _size != r. _size ) return false ;
ListNode< T> * local= this -> _head ;
ListNode< T> * out= r. _head ;
while ( out!= nullptr ) {
if ( out-> data != local-> data ) return false ;
out= out-> _next ;
local= local-> _next ;
} return true ;
} bool operator!= ( const List< T> & r ) const {
return ! ( ( * this ) == r) ;
} const List< T> & operator= ( const List< T> & x ) {
if ( this != & x) {
delete _head;
_head= new ListNode< T> ;
ListNode< T> * tmp= _head-> _next ;
ListNode< T> * tmpx= x. _head -> _next ;
while ( tmp) {
tmp-> _data = tmpx. _data ;
tmp-> _next = tmpx. _next ;
tmp= tmp-> _next ;
tmpx= tmpx. _next ;
} return * this ;
} } List ( T& elem [ ] , int n ) {
for ( int i= n- 1 ; i>= 0 ; i- - ) {
this -> insert ( 1 , elem[ i] ) ;
} } void clear ( ) {
while ( _head-> _next ) erase ( 1 ) ;
} ~List ( ) {
this -> clear ( ) ;
delete this -> _head ;
this -> _head = nullptr ;
this -> _size = 0 ;
} } ;
双向链表模板类(未测试)
template < typename T> class Node {
public :
T data;
Node< T> * next;
Node< T> * prev;
Node ( T data = T ( 0 ) , Node< T> * next = nullptr , Node< T> * prev = nullptr )
: data ( data ) , next ( next ) , prev ( prev ) { } } ;
template < typename T> class List {
private :
Node< T> * head;
Node< T> * tail;
int size;
public :
List ( ) : head ( nullptr ) , tail ( nullptr ) , size ( 0 ) { } void push_front ( T data ) {
Node< T> * node = new Node < T> ( data, head ) ;
if ( head != nullptr ) -> prev = node;
head = node;
if ( tail == nullptr ) = head;
size+ + ;
} void push_back ( T data ) {
Node< T> * node = new Node < T> ( data, nullptr , tail ) ;
if ( tail != nullptr ) -> next = node;
tail = node;
if ( head == nullptr ) = tail;
size+ + ;
} void pop_front ( ) {
if ( head == nullptr ) return ;
Node< T> * node = head;
head = node-> next ;
if ( head != nullptr ) -> prev = nullptr ;
delete node;
size- - ;
} void pop_back ( ) {
if ( tail == nullptr ) return ;
Node< T> * node = tail;
tail = node-> prev ;
if ( tail != nullptr ) -> next = nullptr ;
delete node;
size- - ;
} int length ( ) {
return this -> size ;
} bool empty ( ) {
return size == 0 ;
} ~List ( ) {
while ( head != nullptr ) {
Node< T> * node = head;
head = node-> next ;
delete node;
} = nullptr ;
size = 0 ;
} } ;
顺序栈
实现从略(留坑,期末要复习不完力);
链式栈
实现从略(留坑,期末要复习不完力);
队列
实现从略(留坑,期末要复习不完力);
查找
顺序查找
依次检查顺序表的每一个关键字,空间复杂度为
等概率查找成功的
考虑查找失败情况,
索引查找
将数据分成两个关键字,对总体分块,对每一个块使用顺序查找;
不考虑查找失败的情况下,假设数据分成
明显在分
哈希查找
为降低查找的时间复杂度,可以考虑建立储存数据与储存地址的哈希函数(映射关系):假设要将
哈希冲突处理
开放地址
对于
线性探测再散列:
二次探测再散列:
伪随机探测再散列:
多哈希
设置
链地址法
公共溢出法
设置HashTable和OverTable;
OverTable顺序记录每一个溢出的值;
哈希表查找、性能分析
排序
接下来的排序默认为不减序;
直接插入排序
保持左边序列有序,插入当前的数到左边序列合适的位置;
具体来说,假设
空间复杂度为
适用于数据量较小的、或者几乎已经排好序的数组,此时几乎只需要遍历一遍,时间复杂度接近
插入排序
void insert_sort ( int * s , int n ) { for ( int i= 1 ; i< n; i+ + ) {
if ( s[ i] >= s[ i- 1 ] ) continue ;
int tmp= s[ i] ;
for ( int j= i- 1 ; s[ j] > tmp&& j>= 0 ; j- - ) {
s[ j+ 1 ] = s[ j] ;
s[ j] = tmp;
} } } Shell排序
Shell排序是一种不稳定的排序,平均复杂度为
Shell排序可以分成三步:
选取一个间距
对每个子序列进行插入排序;
减小要选取的间距;
Shell排序
void ShellSort ( int * s , int n ) {
int l= 1 ;
while ( l< n) = 3 * l+ 1 ;
while ( l>= 1 ) {
for ( int i= l; i< n; i+ + ) {
for ( int j= i; j>= l&& s[ j- l] > s[ j] ; j-= l) {
std:: swap ( s[ j] , s[ j- l] ) ;
} } /= 3 ;
} return ;
} 冒泡排序
在每一趟冒泡中,比较相邻两个元素,若逆序则交换,(优化)记录每一趟冒泡最后一次交换发生的位置;
冒泡排序是稳定的,但是时间复杂度为
冒泡排序
void bubble_sort ( int * s , int n ) {
int idx= n- 1 ;
while ( idx> 0 ) {
int expos= 0 ;
for ( int i= 0 ; i< idx; i+ + ) {
if ( s[ i] > s[ i+ 1 ] ) {
std:: swap ( s[ i] , s[ i+ 1 ] ) ;
expos= i;
} } = expos;
} ;
} 选择排序
每一趟找到前面无序部分中最大的数,将它交换到后面有序部分的头部;
选择排序是不稳定的,最坏复杂度为
选择排序
void selection_sort ( int * s , int n ) {
for ( int i= n; i> 1 ; i- - ) {
int Maxpos= 0 ;
for ( int j= 0 ; j< i; j+ + ) {
if ( s[ j] > s[ Maxpos] ) = j;
} std:: swap ( s[ Maxpos] , s[ i- 1 ] ) ;
} return ;
} 基数排序
第二章:递归与分治
主方法
对
第一种情况表明合并子问题复杂度很低,解决问题主要复杂度来源是解决若干个子问题;
第二种情况表明合并子问题复杂度很高,解决问题主要复杂度来源是合并子问题;
第三种情况是合并和解决子问题比较均衡,递归深度为
二分查找
使用二分查找关键字如下(找不到返回-1):
typedef bool ( * fun) ( int * , int , int ) ;
bool judg ( int * a , int m , int key ) {
return a[ m] == key;
} int Find ( int * a , int n , fun judg , int key ) {
int l= 0 ;
int r= n- 1 ;
while ( r>= l) {
int m= l+ ( ( r- l) >> 1 ) ;
if ( judg ( a, m, key ) ) return m;
if ( key< a[ m] ) = m- 1 ;
else l= m+ 1 ;
} return - 1 ;
} int main ( ) {
int n= 11 ;
int a[ 11 ] = { 2 , 7 , 10 , 12 , 16 , 20 , 26 , 32 , 44 , 56 , 62 } ;
int idx= Find ( a, n, judg, 32 ) ;
std:: cout<< idx<< " " ;
return 0 ;
} 二分查找的性能分析:
假设有序表长度为
平均查找长度为
即复杂度为
归并排序
divide:将数组分成均匀两半
sort:递归解决每个半部分
merge:把两部分合并起来组成一个新的排序
一个简单的对整数数组归并排序如下:
void MergeSort ( int * a , int l , int r ) {
if ( r- l< 1 ) return ;
if ( r- l== 1 ) {
if ( a[ l] > a[ r] ) std:: swap ( a[ l] , a[ r] ) ;
return ;
} int m= l+ ( ( r- l) >> 1 ) ;
MergeSort ( a, l, m ) ;
MergeSort ( a, m+ 1 , r ) ;
int tmp[ r- l+ 1 ] = { 0 } ;
int p= 0 , pa= l, pb= m+ 1 ;
while ( pa<= m&& pb<= r) {
if ( a[ pa] < a[ pb] ) {
tmp[ p] = a[ pa] ;
pa+ + ;
p+ + ;
} else {
tmp[ p] = a[ pb] ;
pb+ + ;
p+ + ;
} } while ( pa<= m) {
tmp[ p] = a[ pa] ;
p+ + ;
pa+ + ;
} while ( pb<= r) {
tmp[ p] = a[ pb] ;
p+ + ;
pb+ + ;
} for ( int i= 0 ; i< r- l+ 1 ; i+ + ) {
a[ l+ i] = tmp[ i] ;
} return ;
} 归并排序时一种稳定的算法,可以看到使用
快速排序
选取基准元素pivot;
找到基准元素排序后的位置(实现操作后左边元素均小于它,右边元素均大于它);
维护左端指针low和右端指针high;
high向左扫描,遇到小于pivot元素时停止,交换pivot和该元素;
low向右扫描,遇到大于pivot元素停止,交换pivot和该元素;
high向右扫描..
low向左扫描...
...
直到low==high,基准元素到达这个位置,结束;
划分成子序列,递归地解决问题;
以下是一个对整数数组进行的快速排序代码;
void QuickSort ( int * a , int low , int high ) {
if ( low< high) {
int pivot= a[ low] ;
int l= low;
int r= high;
while ( l< r) {
while ( l< r&& a[ r] >= pivot) - - ;
a[ l] = a[ r] ;
while ( l< r&& a[ l] <= pivot) + + ;
a[ r] = a[ l] ;
} int idx= l;
a[ idx] = pivot;
QuickSort ( a, low, idx- 1 ) ;
QuickSort ( a, idx+ 1 , high ) ;
} } 由于快速排序时一种不稳定的算法,空间平均复杂度为
大数乘法
对于
将大数乘法分解成更小的数,由于移位复杂度是线性的,分治得到复杂度递推式为
得到
由于涉及存储结构和常数优化等问题可能实现还不如常规算法,并且将整数看作多项式利用FFT可以实现
Straseen矩阵乘法
分形
Hanota问题
在经典汉诺塔问题中,有 3 根柱子及 N 个不同大小的穿孔圆盘,盘子可以滑入任意一根柱子。一开始,所有盘子自上而下按升序依次套在第一根柱子上(即每一个盘子只能放在更大的盘子上面)。移动圆盘时受到以下限制:
(1) 每次只能移动一个盘子;
(2) 盘子只能从柱子顶端滑出移到下一根柱子;
(3) 盘子只能叠在比它大的盘子上。
题解:
class Solution {
public :
void move ( std:: vector< int > & A , std:: vector< int > & B ) {
if ( A. empty ( ) ) return ;
B. push_back ( A. back ( ) ) ;
A. pop_back ( ) ;
return ;
} void Hanota ( int n , std:: vector< int > & A , std:: vector< int > & B , std:: vector< int > & C ) {
if ( n== 1 ) {
move ( A, C ) ;
return ;
} Hanota ( n- 1 , A, C, B ) ;
move ( A, C ) ;
Hanota ( n- 1 , B, A, C ) ;
} void hanota ( std:: vector< int > & A , std:: vector< int > & B , std:: vector< int > & C ) {
Hanota ( A. size ( ) , A, B, C ) ;
} } ;
第三章:树与图
二叉树
第
深度为
二叉树边数为
满二叉树、完全二叉树
满二叉树:一棵深度为
完全二叉树:深度为
满二叉树是叶子一个也不少的树,完全二叉树只有最后一层叶子不满,且全部集中在左边,换言之,满二叉树最后一层全是叶子,完全二叉树只有倒数第一层和倒数第二层有叶子;
具有
对完全二叉树,若从上至下、从左至右编号,则编号为
二叉树的存储
顺序存储
结点间关系蕴含在其存储位置中,浪费空间,适于存满二叉树和完全二叉树;
链式存储
遍历
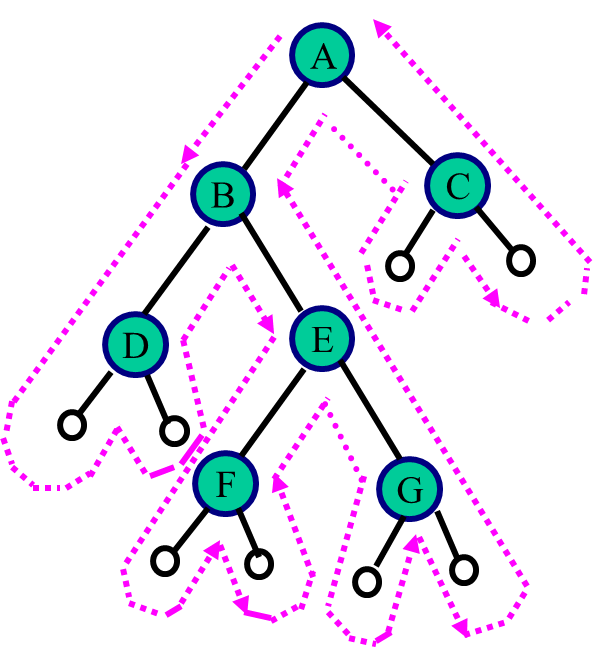
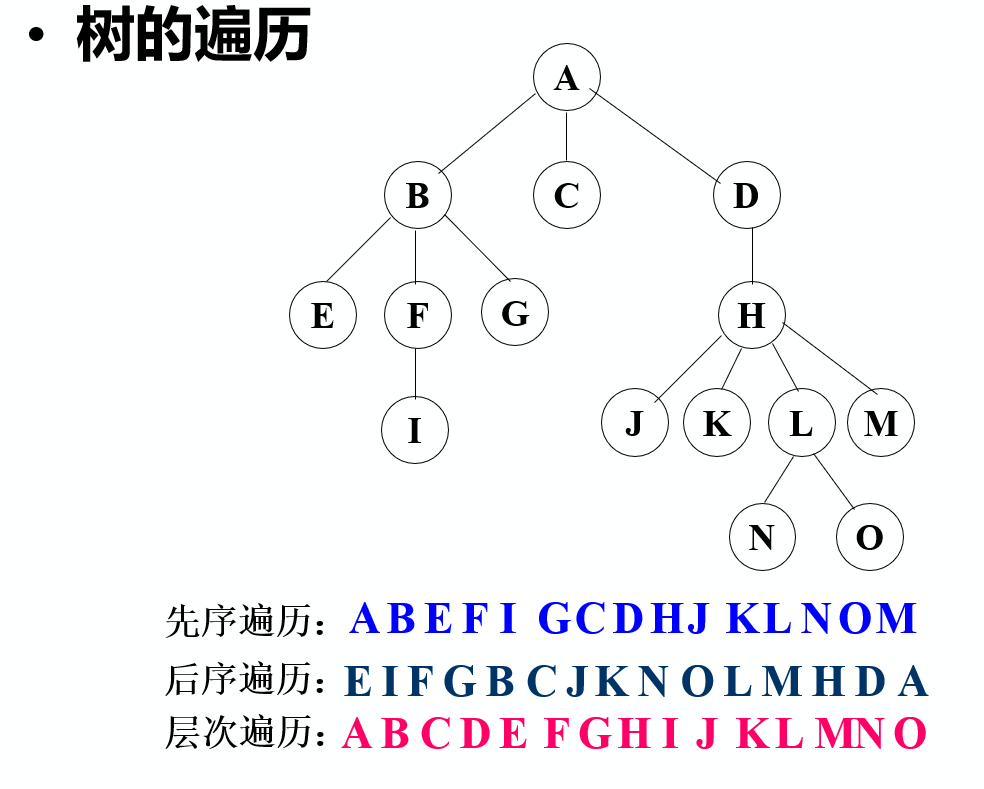
三种方式:先序遍历,中序遍历,后序遍历;
时间复杂度为
访问路径是相同的,只是访问结点的时机不同:
第1次经过时访问=先序遍历
第2次经过时访问=中序遍历
第3次经过时访问=后序遍历
重要结论:
由二叉树的前序序列+中序序列,或由其后序序列+中序序列均能唯一地确定一棵二叉树,
但由前序序列+后序序列却不一定能唯一地确定一棵二叉树。
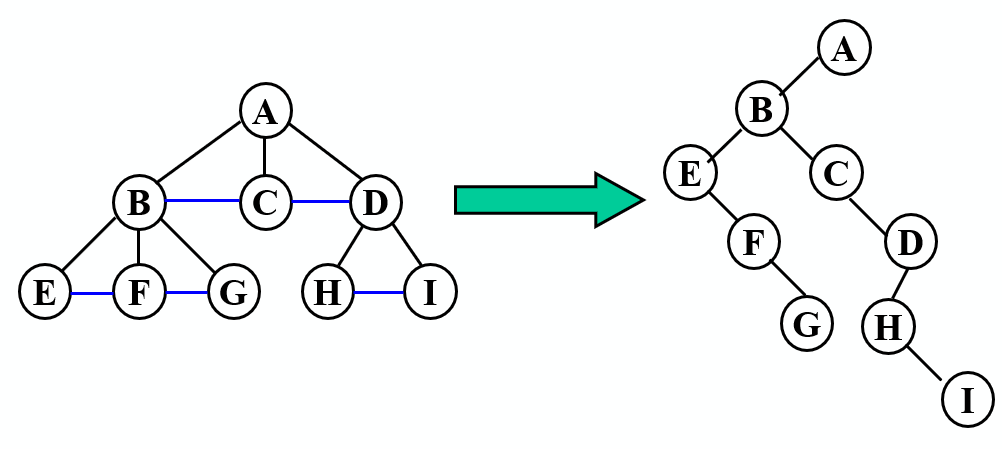
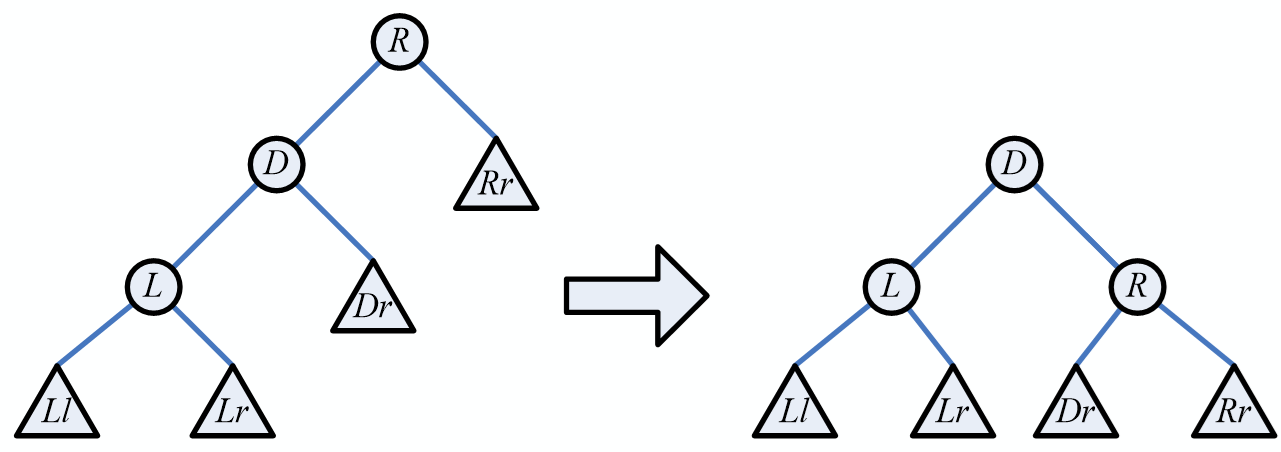
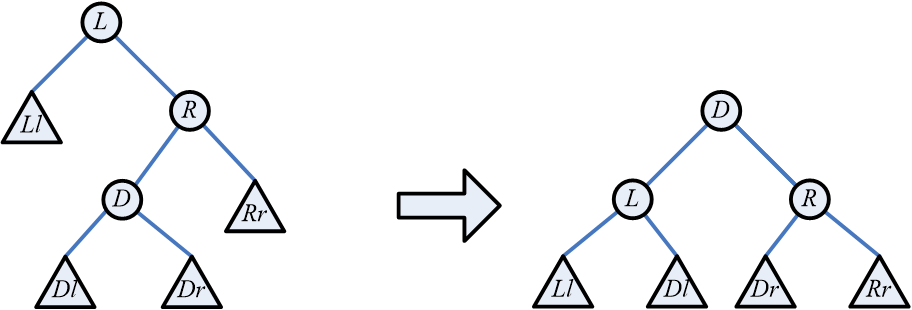
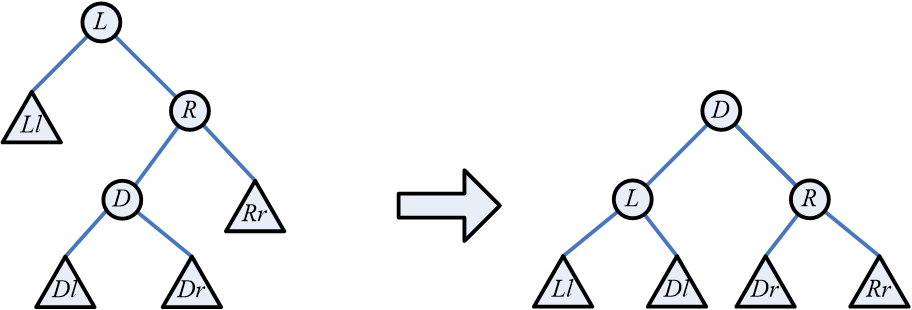
树、二叉树、森林相互转换
加线:将兄弟结点用线相连
抹线:保留双亲与最左边孩子的连线,去掉双亲和其他孩子的连线
旋转:将经过加线和去线以后的结果,进行旋转处理得到转换后的二叉树
树转换成的二叉树,根结点的右子树一定为空
注意,就算是二叉树,通过这种方式转化,结构也可能发生变化;
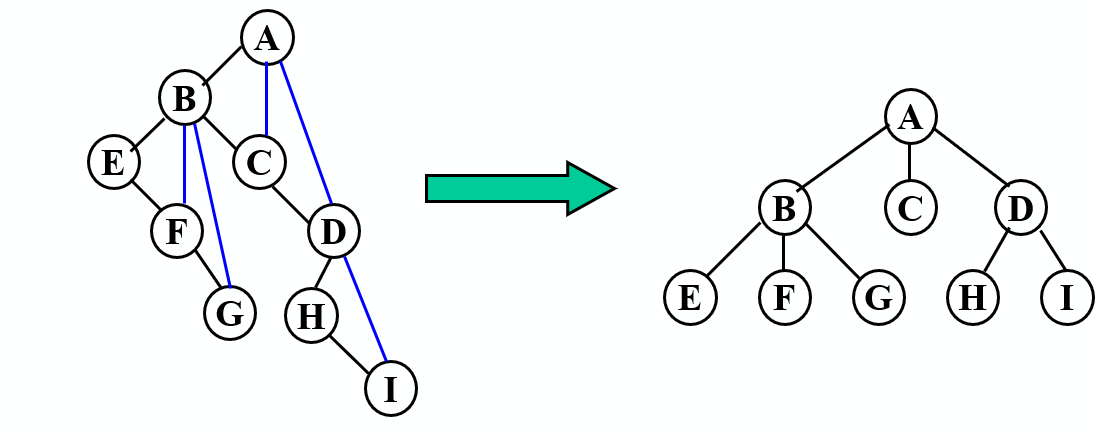
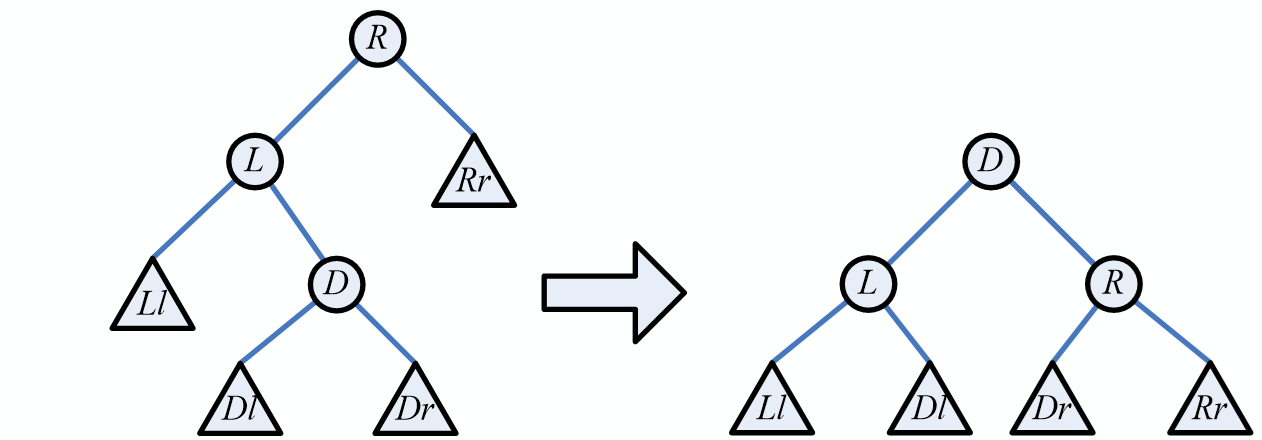
加线:将结点和其左孩子结点的右孩子以及右孩子的右孩子加线相连
抹线:去掉结点和右孩子的连线
旋转:将加线、去线后的结果,进行旋转处理,就得到转换后的树
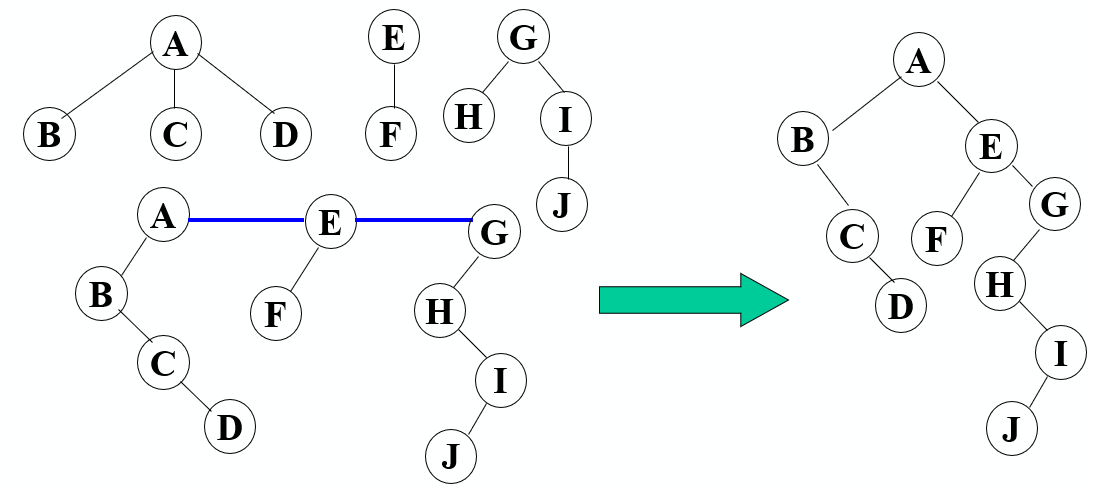
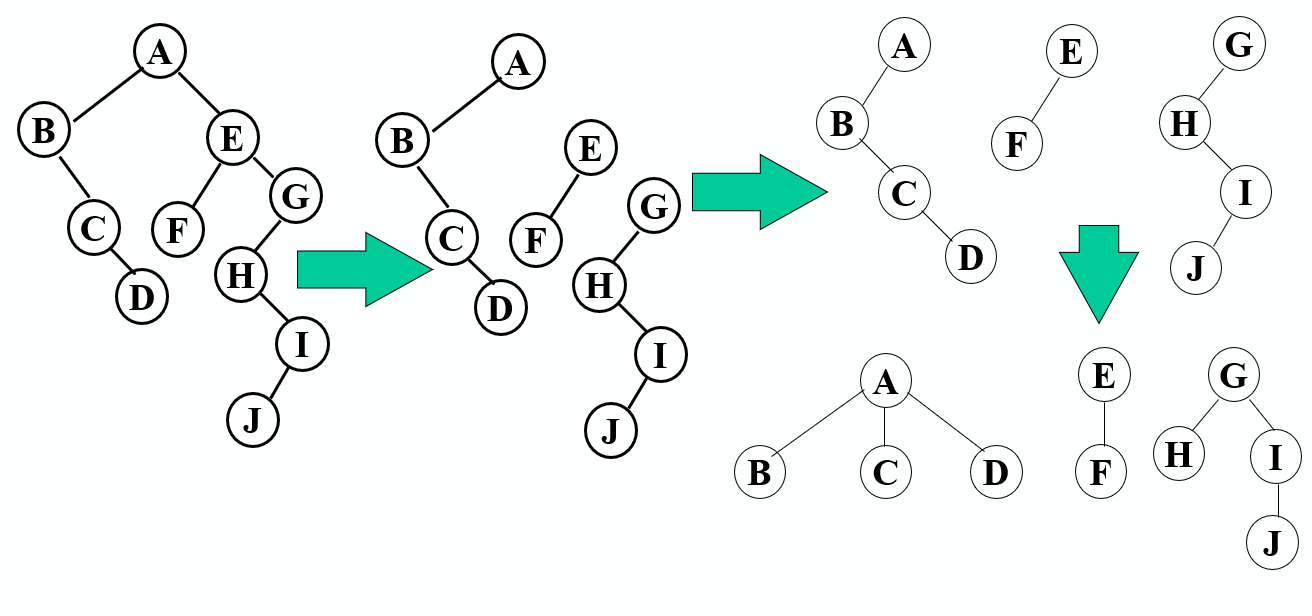
将每棵树分别转换成二叉树,将每棵树的根结点用线相连
以第一棵树根结点为二叉树的根,再以根结点为轴心,顺时针旋转,构成二叉树型结 构;
抹线:将二叉树中根结点与其右孩子连线,及沿右分支搜索到的所有右孩子间连线全 部抹掉,使之变成孤立的二叉树
还原:将孤立的二叉树还原成树;
二叉树模板类
以下是一个简单的二叉树模板类(未测试);
#include < iostream> #include < queue> #include < map> #include < functional> template < typename T> class BTNode {
private :
T data;
BTNode< T> * l;
BTNode< T> * r;
friend class BT;
public :
BTNode ( int val = 0 , BTNode< T> * a = nullptr , BTNode< T> * b = nullptr )
: data ( val ) , l ( a ) , r ( b ) { } ;
~BTNode ( ) {
delete l;
delete r;
} T data ( ) { return this -> data ; } T leftson ( ) { return this -> l ; } T rightson ( ) { return this -> r ; } } ;
template < typename T> class BT {
private :
BTNode< T> * root;
public :
BT ( BTNode< T> * x = nullptr ) : root ( x ) { } ;
DLR ( T* out ) {
if ( ! this -> root ) return ;
* out+ += root. data ( ) ;
root-> l . DLR ( out ) ;
root-> r . DLR ( out ) ;
} LDR ( T* out ) {
if ( ! this -> root ) return ;
root-> l . LDR ( out ) ;
* out+ += root. data ( ) ;
root-> r . LDR ( out ) ;
} LRD ( T* out ) {
if ( ! this -> root ) return ;
root-> l . LRD ( out ) ;
root-> r . LRD ( out ) ;
* out+ += root. data ( ) ;
} LevalTraval ( T* out ) {
std:: queue< BTNode< T> * > q;
BTNode< T> * now= this -> root ;
q. push_back ( now ) ;
while ( ! now) {
* out+ += now-> data ( ) ;
q. pop_front ( ) ;
if ( now-> l ) . push_back ( now-> l ) ;
if ( now-> r ) . push_back ( now-> r ) ;
} } build ( int n , T* pre , T* in ) {
std:: map< int , T> f;
for ( int i= 0 ; i< n; i+ + ) [ in[ i] ] = i;
std:: function< void ( std:: map< int , T> , T* , T* , int , int , int , int ) >
build_tmp= [ ] ( std:: map< int , T> f, T * pre, T* in, int l, int r, int x, int y) {
BTNode* now= new BTNode < T> ( pre[ l] ) ;
this = BT ( now ) ;
int m= f[ pre[ l] ] ;
if ( m!= x) -> l . build_tmp ( f, pre, in, l+ 1 , l+ m- x, x, m- 1 ) ;
if ( m!= y) -> r . build_tmp ( f, pre, in, r- y+ m+ 1 , r, m+ 1 , y ) ;
} ;
build_tmp ( f, pre, in, 0 , n- 1 , 0 , n- 1 ) ;
} int leavesNumber ( ) {
if ( ! this ) return 0 ;
if ( ! root-> l && ! root-> r ) return 1 ;
return root-> l -> leavesNumber ( ) + root-> r -> leavesNumber ( ) ;
} int depth ( ) {
if ( ! this ) return 0 ;
if ( ! root-> l && ! root-> r ) return 1 ;
return 1 + std:: max ( root-> l -> depth ( ) , root-> r -> depth ( ) ) ;
} } ;
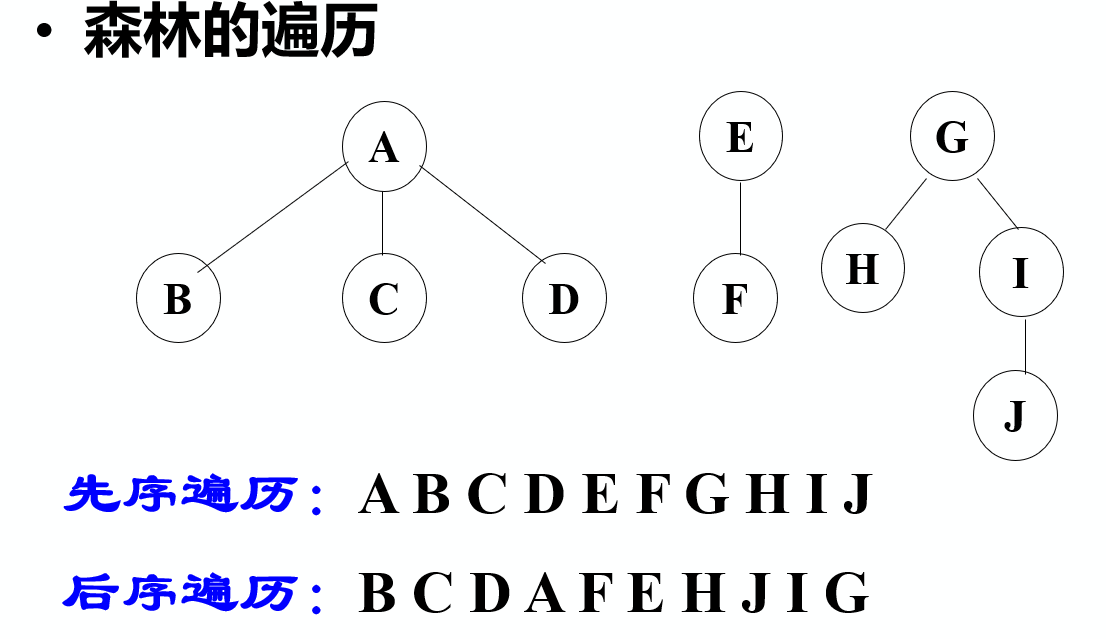
树、森林的遍历
二叉排序树BST
若其左子树非空,则左子树上所有结点 的值均小于根结点 的值;
若其右子树非空,则右子树上所有结点的值均大于等于 根结点的值;
其左右子树本身又各是一棵二叉排序树;
中序遍历 二叉排序树后,得到一个关键字的递增有序序列
查找
若二叉排序树为空,则查找失败,返回空指针;
若查找的关键字等于根结点,成功,返回根结点地址 ;否则
若小于根结点,查其左子树
若大于根结点,查其右子树
平均查找性能:最好
插入
(插入的元素一定在叶结点上)
若二叉排序树为空,则插入结点应为根结点;
否则,继续在其左、右子树上查找
建树
从空树出发,经过一系列的查找、插入操作之后,可生成一棵二叉排序树;
删除
删除叶结点:只需将其双亲结点指向它的指针清零,再释放它即可。
被删结点缺右子树:可以拿它的左孩子结点顶替它的位置,再释放它。
被删结点缺左子树:可以拿它的右孩子结点顶替它的位置,再释放它。
被删结点左、右子树都存在:
可以在它的右子树中寻找中序下的第一个结点(后继填充法),
或是 在它的左子树中寻找中序下的最后一个结点(前驱填充法),用它的值填补到被删结点中,再来处理这个结点的删除问题。
平衡二叉树AVL
对所有结点,左 、 右 子 树 深 度 之 差 平 衡 因 子
对于一个二叉平衡排序树,无论是删除结点还是插入结点,先当作一棵普通的二叉排序树处理,再进行关键的平衡性调整 (下面四张图至关重要);
找到最小不平衡子树
确定
按照下图旋转(四种可能情况)
实现从略(留坑,期末要复习不完力);
红黑树RBT
特点:利用对树中的结点 “红黑着色”的要求,降低了平衡性的条件,达到局部平衡,有着良好的最坏情况运行时间,它可以在
实现从略(留坑,期末要复习不完力);
最优二叉树HuffmanTre
根据给定的n个权值{w1,w2,……wn},构造n棵只有根结点的二叉树。
在森林中选取两棵根结点权值最小的树作左右子树,构造一棵新的二叉树,置新二叉树根结点权值为其左右子树根结点权值之和。
在森林中删除这两棵树,同时将新得到的二叉树加入森林中。
重复上述两步,直到只含一棵树为止,这棵树即霍夫曼树。
实现从略(留坑,期末要复习不完力);
性质:一棵有
图的存储
邻接矩阵
邻接矩阵AdjMartrix[n][n],其中AdjMartrix[u][v]表示边
int vertex[ _MAXSIZE] ; class edge { public :
int head;
int to;
int weight;
char * info;
} ;
edge AdjMartrix[ _MAXSIZE] [ _MAXSIZE] ;
邻接表
由顶点表、边表和基本信息组成(点数,边数)组成,其中边表记录头结点、边权和头结点指向的下一条边;
顶点表记录想要访问的头结点以及顶点信息;
优点:空间效率高,容易寻找顶点的邻接点;
缺点:判断两顶点间是否有边,需搜索两结点对应的单链表,没有邻接矩阵方便
class AdjNode {
public :
int adjvex;
AdjNode * next;
int weight;
} ;
class AdjHead {
public :
int adjvex;
AdjNode * next;
int len;
} ;
class AdjList { public :
AdjHead head[ _MAXSIZE] ;
int vernum;
int edgenum;
} ;
十字链表
将邻接表和逆邻接表拼在一起,查询更加方便;
class edge_ {
public :
int head;
int to;
int weight;
edge* hlink; edge* tlink; } ;
class vertex_ {
public :
int vertex;
edge* firstin;
edge* firstout;
} ;
vertex_ crossLink[ _MAXSIZE] ;
class _edge_ {
public :
bool vis;
int head;
int to;
_edge_* hlink;
_edge_* tlink;
} ;
class _vertex_ {
public :
int first;
_edge_* next;
} ;
_vertex_ node_[ _MAXSIZE] ;
深度优先搜索DFS
一种用于遍历或搜索树或图的算法。所谓深度优先,就是说每次都尝试向更深的节点走;
时间复杂度为
bool vis[ _MAXSIZE] ;
void DFS ( AdjList gra , int now ) { vis[ now] = true ;
AdjHead Now= gra. head [ now] ;
for ( AdjNode* Nxt= Now. next ; Nxt; Nxt= Nxt-> next ) {
int nxt= Nxt-> adjvex ;
if ( ! vis[ nxt] ) {
DFS ( gra, nxt ) ;
} } return ;
} 广度优先搜索BFS
所谓宽度优先。就是每次都尝试访问同一层的节点。 如果同一层都访问完了,再访问下一层。
这样做的结果是,BFS 算法找到的路径是从起点开始的最短 合法路径。换言之,这条路径所包含的边数最小。
在 BFS 结束时,每个节点都是通过从起点到该点的最短路径访问的。
时间复杂度为
void BFS ( AdjList gra , int now ) {
std:: queue< int > q;
q. push ( now ) ;
AdjHead Now= gra. head [ now] ;
while ( ! q. empty ( ) ) {
vis[ q. front ( ) ] = true ;
q. pop ( ) ;
for ( AdjNode* Nxt= Now. next ; Nxt; Nxt= Nxt-> next ) . push ( Nxt-> adjvex ) ;
} } 有向无环图DAG,拓扑排序
经典的Kahn算法
时间复杂度:
求字典序最大/最小的拓扑排序:将 Kahn 算法中的队列替换成最大堆/最小堆实现的优先队列即可,此时总的时间复杂度为
bool TopoSort ( int * out , int * indegree , std:: vector< int > Adj [ ] , int n ) {
std:: queue< int > q;
for ( int i= 1 ; i< n; i+ + ) if ( ! indegree[ i] ) . push ( i ) ;
int cnt= 0 ;
while ( ! q. empty ( ) ) {
int now= q. front ( ) ;
* out+ += now;
cnt+ + ;
q. pop ( ) ;
for ( int j= 0 ; j< Adj[ now] . size ( ) ; j+ + ) if ( ! - - indegree[ Adj[ now] [ j] ] ) . push ( Adj[ now] [ j] ) ;
} return cnt== n; } 最小生成树
Prim算法
Kruskal算法
删除图G=(V,E)的所有边,得到只有n个顶点、没有边的非连通图T=(V,Æ),每个顶点自成一个连通分量
将E中所有的边按照权重从小到大排序;
按照权重从小到大的顺序考察E中每一条边,如果它的两个端点落在不同的连通分量上,则将其加入T中;
重复步骤2,直到所有顶点都在同一连通分量上
最短路径
Dijkstra算法
对于每个点v均维护一个「当前最短距离数组」dis[v]以及「访问数组」vis[v],首先将
dis[u]初始化为0,将其他点的距离初始化为无穷,并将所有点初始化为未访问的。记
e[i]:u-v的边权e[i].w。然后进行以下步骤:
从所有未访问的点中,找出当前距离最小的,并将其标记为已访问的;
调整所有出边连接但尚未访问 的点,转移状态;
重复1和2步骤,直到所有点都已访问,因为所有边权权值均为正的,所以用之后访问的结点是不能更新已经访问过的结点的(因为贪婪算法下若可以更新的话必定在还在之前就已经更新过了);
可以用pre[y]=i维护最短的路径(点边关系);
Floyd算法
考虑对每个
第四章:线性规划