SQL语言
对于SQL语言来说,
- 以同一种语法结构提供两种使用方法:既是自含式语言,又是嵌入式语言
- 语言简洁,易学易用,核心功能只需9个动词 DDL(数据定义语言):CREATE、DROP、ALTER DML(数据操纵语言): SELECT、INSERT、UPDATE、DELETE DCL(数据控制语言):GRANT、REVOKE
以下式SQL Server的包含的数据类型:
| 数据类型 | 功能及特点 |
|---|---|
| char(n) | 固定长度字符串,长度范围是1~8000,默认值为1。 |
| nchar(n) | 固定长度Unicode字符串,长度范围是1~4 000,默认值为1。 |
| varchar(n) | 变长字符串,长度范围是1~8 000,如省略n,则默认最大长度是1。 |
| nvarchar(n) | 包含n个字符的可变长度Unicode字符数据,n的取值介于1与4000 之间;如省略n,则默认长度是1。 |
| text | 变长字符数据,最多达到字节,行中存储指向第一个数据 页的指针,实际的文本是以B-树页面存储。 |
| ntext | 变长Unicode字符数据,最多可达字节,行中存储指向第一个数据页的指针,实际的文本是以B-树页面存储。 |
| dec(n,m) decimal(n,m) numeric(n,m) | 数值型,n是位数,范围是1~38,m是小数点右边的位数,范围是 0~n。可用decimal(n)表示decimal(n,0);如果用不带参数的decimal时,系统默认表示decimal(38,0),但是,这时SQL Server最大可达到28位。推荐decimal使用明确的n,有助于提高程序的清晰度。 |
| int,integer | 四字节二进制整数,范围是。 |
| float(n) | 浮点数,n是尾数位数,范围是1~53。如果n为1~24则指定单精度 (4字节),如果n为25~53则指定双精度(8字节);注意:可以使用Float本身表示Float(53)。 |
| Real | 等价于Float(24),Real列有7位数精度。 |
| Smalldatetime | 四字节日期和时间,日期范围是~6-6-2079;时间精度是自午夜开始的1分钟之内。 |
| Datetime | 八字节日期和时间,日期范围是~12-31-9999,时间精度:3.33毫秒之内。 |
| Binary(n) | 定长二进制数据,长度范围是1~8 000字节,如省略n,则默认值是1。 |
| Varbinary(n) | 变长二进制数据,长度从1~8 000字节,如省略n,则默认值是1。 |
数据库创建
为了创建数据库,用户必须是系统管理员或者被授权使用CREATE DATABASE语句,语法形式如下:
CREATE DATABASE <数据库名>
[<On Primary>
% 一个数据库可建多个档案文件,主档案文件是会有一个,默认在主档案文件
([Name = 系统使用的逻辑名],
[Filename = 完全限定的NT Server文件名],
[Size = 文件的初始大小],
[MaxSize = 最大的文件尺寸],
[FileGrowth = 系统的扩展文件量])…]
[<Log On>
([Name = 系统使用的逻辑名],
[Filename = 完全限定的NT Server文件名],
[Size = 文件的初始大小],
[FileGrowth = 系统的扩展文件量])]
创建表操作如下:
CREATE TABLE 基表名(
<列名1> <列类型> <列约束>,
<列名2> <列类型> <列约束>,
…
<列名n> <列类型> <列约束>,
< 表约束> | [ { PRIMARY KEY | UNIQUE } [ ,…] ]
)
表名形式为:[数据库名[.拥有者.]]表名
例如:
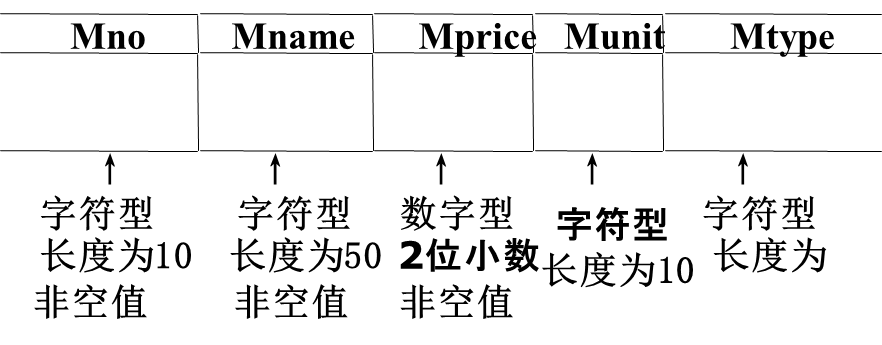
(
Mno VARCHAR(10) PRIMARY KEY,
Mname VARCHAR(50) NOT NULL,
Mprice DECIMAL(18,2) NOT NULL,
Munit VARCHAR(10) DEFAULT '克',
Mtype VARCHAR(10)
)
常用完整性约束
-
主码约束: PRIMARY KEY
-
唯一性约束:UNIQUE
-
非空值约束:NOT NULL
-
参照完整性约束:Foreign Key?
- 含有主键或者唯一性约束列的表为主表(或父表),含有外键的表为从表(或子表)。
- 参照完整性:外键约束指定外键的列与主表中主键或者唯一性约束列相关联,也就是说,外键的每一个值至少能在主表的主键或唯一性约束列中找到一个相同的列值。
- 外键是在从表上定义,当修改或删除主表的记录,或者在从表上修改或插入数据时,由数据库管理系统自动进行检查。
- 在需要命名约束、多列约束或定义外键约束时,必须使用
CONSTRAINT关键字。在简单约束(如单列主键、唯一约束、检查约束和默认值)中,可以省略CONSTRAINT关键字。
-
以下是外键的一个示例:
CREATE TABLE RecipeMaster ( Rno VARCHAR(10) PRIMARY KEY, Pno VARCHAR(10) NOT NULL, Dno VARCHAR(10) NOT NULL, DGno VARCHAR(10), Rdatetime DATETIME, ) CREATE TABLE RecipeDetail ( Rno varchar (10) , Mno varchar (10) , Mamount decimal(18, 0), CONSTRAINT Rnofk FOREIGN KEY(Rno) REFERENCES RecipeMaster(Rno), CONSTRAINT mnofk FOREIGN KEY(Dno) REFERENCES medicine(Mno) );
数据库修改
Alter用于修改现有的数据库对象(如表结构、添加或删除列),Alter Database语法如下:
ALTER DATABASE <数据库名>
[<Add File>
(<Name = 系统使用的逻辑名>,
[Filename = 完全限定的NT Server文件名],
[Size = 文件的初始大小],
[MaxSize = 最大的文件尺寸],
[FileGrowth = 系统的扩展文件量])…]
[<Modify File>
(<Name = 系统使用的逻辑名>,
[Filename = 完全限定的NT Server文件名],
[Size = 文件的初始大小],
[MaxSize = 最大的文件尺寸],
[FileGrowth = 系统的扩展文件量])…]
[<Remove File> <系统使用文件的逻辑名>,…]
[<Add Log File>
(<Name = 系统使用的逻辑名>,
[Filename = 完全限定的NT Server文件名],
[Size = 文件的初始大小],
[MaxSize = 最大的文件尺寸],
[FileGrowth = 系统的扩展文件量])…]
我们对表的修改通常采用以下语句
ALTER TABLE 〈基表名〉
[ ALTER COLUMN <列名> <数据类型>],
[ ADD <新列名> <数据类型> <约束规则>],
[ DROP <列名>],
[ DROP <约束规则>];
<表名>:要修改的基本表
ADD子句:增加新列和新的完整性约束条件
DROP子句:删除指定的完整性约束条件
ALTER子句:用于修改列名和数据类型
例如:
ALTER TABLE RecipeDetail ADD Price Decimal ( 5,3 )
数据库删除
删除数据库的命令格式为: DROP DATABASE 需要删除的数据库名
我们对表的删除往往采用以下语句:
DROP TABLE <表名> [RESTRICT|CASCADE];
RESTRICT:拥有表的对象(Check、Foreign Key、视图、触发器、存储过程、函数等)时禁止删除;
CASCADE:级联删除表的所有对象
不同数据库产品略有执行策略的差别
使用ALTER TABLE语句还可以从表中删除已有的列,但删除列之前,必须删除任何引用该列的约束、缺省表达式、计算列表达式或索引。
例如:
DROP TABLE employees;
数据查询
数据查询通常采用如下格式:
SELECT [ALL|DISTINCT] <目标列表达式> [,<目标列表达式>] …
[INSERT INTO <新表名>]
FROM <表名或视图名>[, <表名或视图名> ] …
[ WHERE <条件表达式> ]
[ GROUP BY <列名1> [ HAVING <条件表达式> ] ]
[ ORDER BY <列名2> [ ASC|DESC ] ];
SELECT子句:指定要显示的属性列
FROM子句:指定查询对象(基本表或视图)
WHERE子句:指定查询条件
GROUP BY子句:对查询结果按指定列的值分组,该属性列值相等的元组为一个组。通常会在每组中作用集函数。
HAVING短语:筛选出只有满足指定条件的组
ORDER BY子句:对查询结果表按指定列值的升序或降序排序
-
最简单例子:查询医生基本信息表中所有医生的所有信息。
SELECT * FROM Doctor -
指定列别名:查询显示指定的列,列的显示顺序与SELECT子句后指定的列顺序一致,这与关系代数的投影操作功能一致。查询显示各列的标题可以是列名,也可以改变查询显示列的标题。
SELECT Dname 医生姓名, Dlevel 专业职称 FROM Doctor
-
无重复记录:关键字DISTINCT是合并查询结果中的重复记录,当没有DISTINCT时,表示显示所有记录。
SELECT DISTINCT Ddeptno FROM Doctor -
条件查询
在SELECT命令中使用WHERE子句给出查询条件来实现;
运 算 符 具 体 含 义 = 等于 <>或!= 不等于 < 小于 <=或!> 小于等于 > 大于 >=或!< 大于等于 NOT 逻辑非,用于选择不满足条件的记录行 AND 逻辑与,用于选择同时满足多个条件的记录行 OR 逻辑或,用于选择满足任意一个条件的记录行 IN 属于集合(或查询返回值构成的集合) NOT IN 不属于集合(或查询返回值构成的集合) BETWEEN A AND B 大于或等于A且小于或等于B LIKE 模式匹配,“%”表示匹配任意多个字符,“-”匹配一个字符 NOT LIKE 为LIKE的否定形式 IS NULL 为空值 IS NOT NULL 为非空值 例如:
SELECT * FROM Doctor WHERE Dsex='男' Select * From Doctor Where Dlevel Like '副%' SELECT * FROM Doctor WHERE Dsex='男' AND Dage<=40 SELECT * FROM Doctor WHERE DDdeptno IN ('102','103','201') -
使用ORDER BY子句查询
-
通常在查询时,需要按一定顺序显示,可以使用ORDER BY子句列进行排序,ASC和DESC分别表示升序和降序,用户可以任选,系统缺省为升序。
-
如果按多列进行排序,应分别指出用于排序的列名及相关的升序或降序方式,排序方式的先后顺序与ORDER BY后面排序列的顺序一致。即首先由ORDER BY后面的第一列确定顺序,其次由第二列确定顺序,再由第三列确定顺序……依此类推。
-
在SQL SERVER中,空值为最小。
-
例如按照年龄升序查询男医生信息
SELECT * FROM Doctor WHERE Dsex='男' ORDER BY Dage ASC
-
-
聚集查询
统计医生人数
SELECT COUNT(Dno)人数 FROM Doctor统计平均年龄
SELECT AVG(年龄) FROM 作者 -
多表间的连接查询
-
多表查询的理论基础是关系运算。
-
多表间的连接运算遵循笛卡尔规则,但“笛卡尔”查询会产生大量的无意义的数据记录。因此,在进行连接时加上一些限制条件,使产生的数据记录是笛卡尔连接结果集的子集。
-
进行连接运算的表,必须存在着有某种关系的公共列,连接运算实际是比较各表的公共列值,如果满足条件的连接产生组合输出行。
-
格式如下,为了避免相同列名出现在同一查询的多个表(或视图)中引起二义性,则需要在列的前面加上限定前缀,可以使用表名或表的别名作为前缀。 “表名 别名” 或 “表名AS别名”
SELECT <查询列表> [ INTO <新表名> ] FROM <基表名1|视图名1> [ 别名1 ] [,<基表名2|视图名2> [ 别名2 ]] …… WHERE <别名1.列名1> 比较运算符 <别名2.列名2>…… [ GROUP BY <分组条件>] [ HAVING <分组后筛选条件>] [ ORDER BY <排序列名>[ ASC | DESC ] ]SELECT <查询列表> [ INTO <新表名> ] FROM <基表1|视图1> [ AS 别名1 ] {< LEFT | RIGHT | FULL > [ OUTER ] JOIN} <基表2|视图2> [AS 别名2 ] ON <连接条件> -
一个自然连接的例子如下:
SELECT Rno,Pno,D.Dno,Dname,Dsex,Dage,Ddeptno,Dlevel FROM RecipeMaster R, Doctor D WHERE R.Dno=D.Dno -
一个外连接的例子如下:
SELECT DeptName 部门名称,DName 医生姓名 FROM Dept left outer join Doctor ON Dept.DeptNo=Doctor.Ddeptno
-
数据增加
用VALUES插入,格式为:
INSERT INTO <基表名> [(<列名表>)] VALUES(<值表>)
<基表名>是指要插入数据的目标表;
<列名表>是指定目标表的目标列,该参数可以省略;如果省略列名表,表示向目标表所有列插入数据;
<值表>是指定具体要插入的值。
一个例子如下:
INSERT
INTO Doctor(Dno,Dname,Dsex,Dage,DDeptNO,Dlevel)
VALUES('145','王军','男',28,'101','医师')
数据修改
数据修改格式如下:
UPDATE<基表名>
SET <列名1>=<表达式2>,<列名2>=<表达式2>…
[WHERE <条件表达式>]
一个例子如下:在医院数据库中,将编号为“423”的患者的社会保障号,修改为“20073425”。
UPDATE Patient
SET Pino='20073425'
WHERE Pno='423'
数据删除
数据删除格式如下:
DELETE FROM <表名>[WHERE<条件>]
一个例子如下:在医院数据库中,将编号为“423”的患者从系统中删除
DELETE FROM Patient WHERE Pno='423'
索引
建立索引是加快查询速度的有效手段,索引由DBMS内部实现,属于内模式范畴
- 建立索引:DBA或表的属主(即建立表的人)根据需要建立,有些DBMS自动建立以下列上的索引: PRIMARY KEY和 UNIQUE
- 维护索引:DBMS自动完成
- 使用索引:DBMS自动选择是否使用索引以及使用哪些索引
创建索引格式如下:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX <索引名>
ON < 基表名 | 视图名> ( 列名[ ASC | DESC ] [ ,...n ] )