Adversarial Search
对抗搜索也称为博弈搜索:在一个竞争环境中,两个或两个以上的Agents之间通过竞争实现相反的利益,一方最大化这个利益,另外一方最小化这个利益。
Games
对于人工智能方向的博弈,往往有以下分类:
-
Deterministic (确定性的)&stochastic (随机性的)?
-
One, two, &more players?
-
Zero sum?(零和游戏:对一方有利的东西将对另一方同等程度有害,不存在“双赢”结果)
-
Perfect information (states完全可被观察)?
我们通常用以下形式化描述博弈:
- States: 状态空间,初始状态为;
- Players:行动玩家集合;
- Actions: 某状态下的合法行动集合;
- Transition Function(Result): 转移模型
- Terminal Test:终止测试,判断game是否结束;
- Terminal Utilities: 效用函数,描述游戏者在终止状态下的数值,, 在零和博弈中,玩家总收益 之和一样;
- Policy:玩家采取的策略
其中,Actions, Result定义这个游戏的博弈树:结点是状态,边是此时合法的行动,对于双人博弈来说,奇数层MAX希望效用值最大化,偶数层MIN希望效用值最小化;
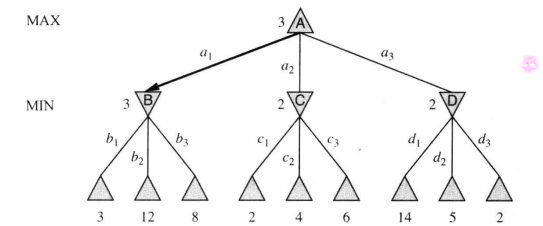
给定一棵博弈树,最优策略可以通过检查每个结点的极小极大值来确定,终止状态的极小极大只就是自身的效用值;
对于给定的选择,MAX希望移动到到达极大值的状态,MIN希望移动到极小值的状态;
Minimax Search
对于简单的博弈问题,可以生成整棵博弈树,找到必胜策略;对于复杂的博弈问题,不可能生成整个搜索树;
一种可行的方法是用当前正在考察的节点生成一棵部分博弈树,并利用代价函数对叶节点进行估值;
对于一棵状态搜索树,玩家交替行棋,已知叶子结点(终止状态)的效用值,求每个结点的Minimax值,也就是best achievable utility;
Minimax就是这样的一个递归算法,一直向下进行到叶节点然后随着递归的展开通过搜索树倒推极小化极大值;
def max-value(state):
initialize v = -∞
for each successor of state:
v = max(v, value(successor))
return v
def min-value(state):
initialize v = +∞
for each successor of state:
v = min(v, value(successor))
return v
def value(state):
if the state is a terminal state:
return the state’s utility
if the next agent is MAX:
return max-value(state)
if the next agent is MIN:
return min-value(state)
对于上面举例的两层博弈树,max在根节点的最佳移动是,因为它指向值最高的状态;而min的最佳响应是,因为它指向值最低的状态。
上述的递归程序时间开销是指数级的,完全不使用,我们考虑一个能得到相同结果,剪去不影响结果的搜索分支的剪枝方式;
注意到Minimax Search是一种深度优先的搜索,因此只需要考虑书上某一单一路径上的结点,对于每一个结点,维护两个参数:
- :目前未知路径上发现的MAX的最佳选择;
- :目前为止的路径上发现MIN的最佳选择;
通过维护这两个参数,我们可以省去一些结点的Minimax值计算;
def max-value(state, α, β):
initialize v = -∞
for each successor of state:
v = max(v, value(successor, α, β))
if v ≥ β
return v
α = max(α, v)
return v
def min-value(state , α, β):
initialize v = +∞
for each successor of state:
v = min(v, value(successor, α, β))
if v ≤ α
return v
β = min(β, v)
return v
def value(state):
if the state is a terminal state:
return the state’s utility
if the next agent is MAX:
return max-value(state, -∞, +∞)
if the next agent is MIN:
return min-value(state, -∞, +∞)
以下是一个较为复杂的样例:
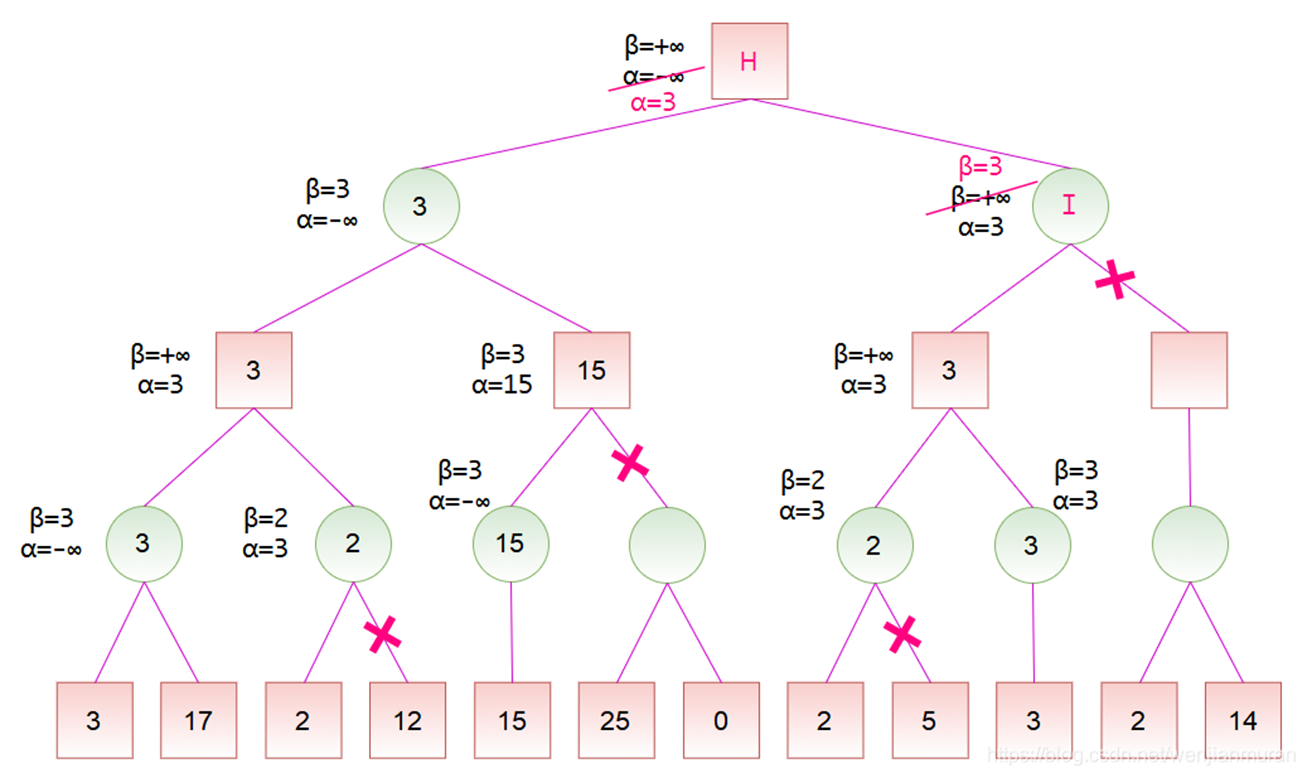
可以看到,经过剪枝,原本需要访问26个结点的搜索树,现在只需要访问17个结点就得到了根的Minimax值,该技术能有效减少访问搜索树中的结点个数;
行棋排序
剪枝算法的效率很大程度上取决于检查后继状态的顺序,但是对于状态做出排序事实上是困难的,假设后继状态检查采取的是随机顺序,检查的总结点树大约是;
对重复状态的搜索可能会导致搜索代价的指数级增长,不同的行棋顺序可能会导致相同的结果,因此需要将第一次遇到的棋局以及评估值用Hash表存储起来,一般称为换位表;
如果评估的速度过快,那么换位表就不太可能保存所有评估了,也许保留一些有价值的结点可能是比较好的方案;
不完美的实时决策
由于下棋的时间有限,所以Agent应该尽早截断搜索,将启发式评估函数值近似为终端结点的Minimax值,假设为截断搜索的最大深度,截断测试表示为CUTOFF(s,d)转移方程应变为:
为了避免Agent出昏招,评估函数对终止状态的排序要和真正的效用函数排序结果一样;
评估函数的计算开销不能太大,而且应该和取胜几率密切相关;
假如说对于国际象棋这种状态完全可观察的博弈问题来说,可以由子力价值,关键位置,王的安全性等等,这往往是设计者的先验知识;
我们从不同的角度评估棋局,最终可得到一个加权平均的方案作为评估函数值如下:
对于更复杂的博弈问题,人们往往很难总结经验,也许机器学习的技术将更有利于确定评估函数的权值,比如一个象值三个兵;